数据结构 压缩 Trie 树 - Radix 树
最近学习 Gin 框架,一直看到它使用了 Radix 树,占用内存更少;就开始好奇这是个啥,与 HashMap 有啥区别,这里转载大佬的博客,彻底解决这个问题。
转载自 图解Redis中的Radix树,后半 Redis 的部分转载自 Redis · 引擎特性 · radix tree 源码解析
在 Redis 里,有好几个地方都用到了 Radix 树。比如阿里的 Redis 的每个 slot 槽里存储的 key 就是使用了 Radix 树。还有 Redis 5.0 发布的一个新功能 Stream 也有用到 Radix 来存储 key。
你也许会想通过 key 查找 value,为什么不通过 HashMap 之类的,java 的小伙伴肯定知道 hash 对于大量的 key 的 hash 后最后还是要落到链表(现在变成了红黑树)。所以 hash 这个被认为只适合少量的数据存储查找,多了遭不住,而且还要 rehash 之类的操作,肯定不能用这个来搞定 Redis 的 key 存储。这会你也许想过使用红黑树这样的平衡树来存储 Redis 的 key。这确实是个不错的方案,但红黑树也被认为是有一些性能问题,而且在 Redis key 检索的场景下,也许会有更适合的算法来 hold 住。
为此 Redis 的大佬们决定使用 Radix 树来解决问题。Radix 树是从哪里来的呢?是从 Trie 树来的。我们先来简单的了解一下 Trie 长啥样。
Trie 树
Trie Tree,字典树。Trie Tree 的原理是将每个 key 拆分成每个单位长度字符,然后对应到每个分支上,分支所在的节点对应为从根节点到当前节点的拼接出的 key 的值。它的结构图如下所示:
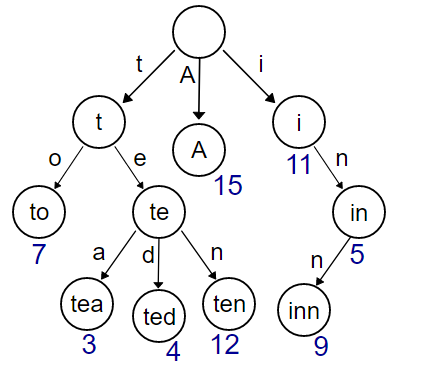
Trie 树的细节可以看 数据结构 Trie Tree 前缀树 字典树 这篇笔记
大体就长这样,可以看出 Trie 树已经很厉害了。Trie 树把很多的公共前缀独立出来共享了,这样避免了很多重复的存储。想想字典集的方式,一个个的 key 被单独的存储,即使他们都有公共的前缀也要单独存储。相比字典集的方式,Trie 树显然节省更多的空间。
现在我们就演绎下 Trie 树是如何浪费内存和空间的。比如下面的一组数据:
{
"deck": someValue,
"did": someValue,
"doe": someValue,
"dog": someValue,
"doge": someValue,
"dogs": someValue
}
用 Trie 树的画法把上面的 key value 画出来如下:
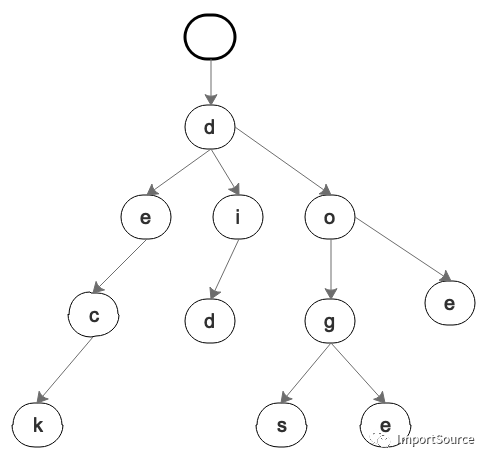
Radix 树:压缩后的 Trie 树
也许你已经发现了一些问题。比如 "deck" 这一个分支,有没有必要一直往下来拆分吗?还是 "did",有必要 d,然后 i,然后 d吗?像这样的不可分叉的单支分支,其实完全可以合并,也就是压缩。像下面这样:

这样看起来是不是要更节省一点空间呢?这只是 6 个单词的样子,数据越多,空间节省的效果越明显。而且这样压缩后,不可分叉的分支高度也变矮了。我们叫这样的 Trie 树为压缩 Trie 树(Compressed Trie Tree)。
压缩 Trie 树也就是今天的主角 Radix 树,只不过他有多个名字,有人叫压缩 Trie 树,有人叫 Radix 树。
Redis 中就用到了 Radix 树。
Radix 树: 在计算机科学中,基数树(Radix Trie,也叫基数特里树或压缩前缀树)是一种数据结构,是一种更节省空间的 Trie(前缀树),其中作为唯一子节点的每个节点都与其父节点合并,边既可以表示为元素序列又可以表示为单个元素。 因此每个内部节点的子节点数最多为基数树的基数 r ,其中 r 为正整数,x 为 2 的幂,x≥1,这使得基数树更适用于对于较小的集合(尤其是字符串很长的情况下)和有很长相同前缀的字符串集合。
基数树的查找方式也与常规树不同(常规的树查找一开始就对整个键进行比较,直到不相同为止),基数树查找时节点时,对于节点上的键都按块进行逐块比较,其中该节点中块的长度是基数 r;
当 r 为 2 时,基数树为二进制的(即该节点的键的长度为 1 比特位),能最大程度地减小树的深度来最小化稀疏性(最大限度地合并键中没有分叉的节点)。 当 r ≥ 4 且为 2 的整数次幂时,基数树是 r 元基数树,能以潜在的稀疏性为代价降低基数树的深度。
应用:
- 基数树可用来构建关联数组。
- 用于 IP 路由。
- 信息检索中用于文本文档的倒排索引。(Inverted index 指的是将单词或记录作为索引,将文档 ID 作为记录,这样便可以方便地通过单词或记录查找到其所在的文档,说来这个倒排索引应该翻译成反向索引才对,,,,)
操作 基数树支持插入、删除、查找操作。查找包括完全匹配、前缀匹配、前驱查找、后继查找。所有这些操作都是 O(k) 复杂度,其中 k 是所有字符串中最大的长度。
计算机是怎么处理 Radix 树的呢?
现在还没完,因为计算机可不会像人类一样可以通过英文像上面的图一样来构建树,计算机只认识 0 和 1。所以为了真正的了解 Radix树,我们需要知道机器是怎么读取 Radix 树的。计算机对于 Radix 树的处理是以 bit(或二进制数字)来读取的。一次被对比 r 个 bit,2 的 r 次方是 radix 树的基数。这也是基数树的这个名字的由来。
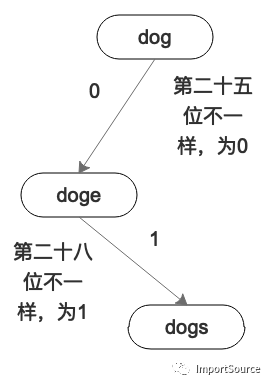
现在我们把上面的三个单词变成二进制的样子,然后一位一位的看:
dog: 01100100 01101111 01100111
doge: 01100100 01101111 01100111 01100101
dogs: 01100100 01101111 01100111 01110011
按照字符串的比对,你会发现 dog 是 dogs 和 doge 的子串。
但我们现在比对二进制,一位一位的比对,你会发现 dog 和 doge 是在第二十五位的时候不一样的。dogs 和 doge 是在第二十八位不一样的。按照位的比对的结果,你会发现 doge 居然是 dogs 二进制子串。秀不秀?
这就是计算机的方式。
Redis 是如何实现 Radix 树的呢?
raxNode 是 radix tree 的核心数据结构,其结构体如下所示:
typedef struct raxNode {
uint32_t iskey:1; //是否包含key,
uint32_t isnull:1; //是否有存储value值,比如存储元数据就只有key,没有value值。value值也是存储在data中
uint32_t iscompr:1; //是否做了前缀压缩
uint32_t size:29; //该节点存储的字符个数
unsigned char data[]; //存储子节点的信息
} raxNode;
插入 key
下面我们就以插入场景为例(各场景间无关联),挨个插入几个字符串。假设 j 是遍历已有节点的游标,i 是遍历新增节点的游标。
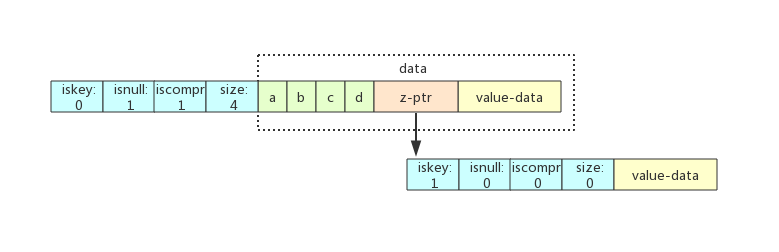
场景一:只插入 abcd
z-ptr 指向的叶子节点 iskey=1,使用了压缩前缀。
场景二:在 abcd 之后插入 abcdef
从 abcd 父节点的每个压缩前缀字符比较,遍历完所有 abcd 节点后指向了其空子节点,j = 0, i < len(abcded)。
查找到 abcd 的空子节点,直接将 ef 赋值到子节点上,成为 abcd 的子节点。ef 节点被标记为 iskey=1,用来标识 abcd 这个 key。ef 节点下再创建一个空子节点,iskey=1 来表示 abcdef 这个 key。
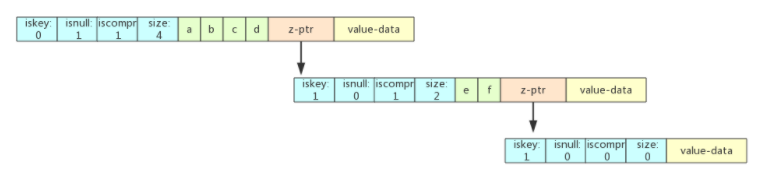
场景三:在 abcd 之后插入 ab
ab 在 abcd 能找到前两位的前缀,也就是 i=len(ab),j < len(abcd)。
将 abcd 分割成 ab 和 cd 两个子节点,cd 也是一个压缩前缀节点,cd 同时被标记为 iskey=1,来表示 ab 这个 key。
cd 下挂着一个空子节点,来标记 abcd 这个 key。
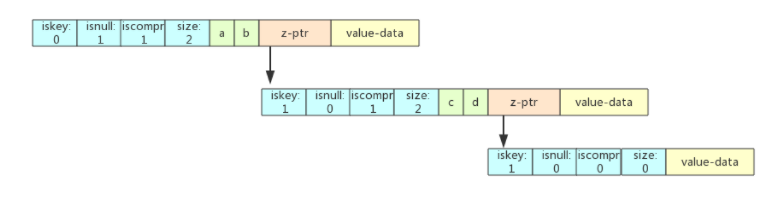
场景四:在 abcd 之后插入 abABC
abcABC 在 abcd 中只找到了 ab 这个前缀,即 i < len(abcABC),j < len(abcd)。这个步骤有点复杂,分解一下:
- step 1:将abcd从ab之后拆分,拆分成ab、c、d 三个节点。
- step 2:c节点是一个非压缩的节点,c挂在ab子节点上。
- step 3:d节点只有一个字符,所以也是一个非压缩节点,挂在c子节点上。
- step 4:将ABC 拆分成了A和BC, A挂在ab子节点上,和c节点属于同一个节点,这样A就和c同属于父节点ab。
- step 5:将BC作为一个压缩前缀的节点,挂在A子节点下。
- step 6:d节点和BC节点都挂一个空子节点分别标识abcd和abcABC这两个key。
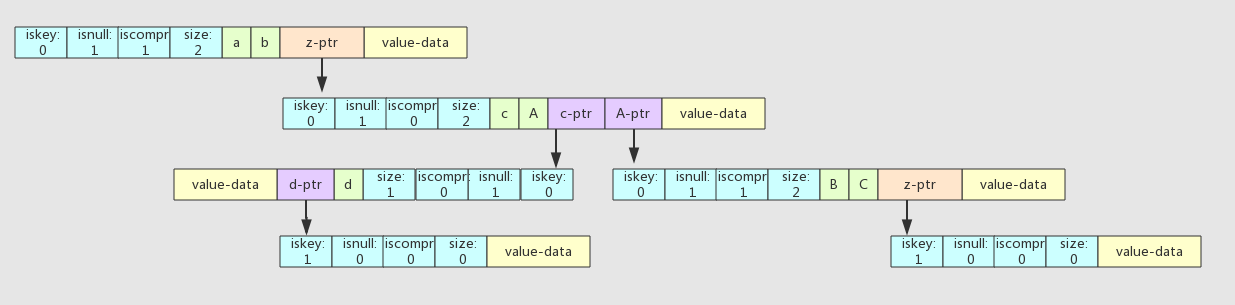
场景五:在 abcd 之后插入 Aabc
abcd 和 Aabc 没有前缀匹配,i = 0,j = 0。
将 abcd 拆分成 a、bcd 两个节点,a 节点是一个非压缩前缀节点。
将 Aabc 拆分成 A、abc 两个节点,A 节点也是一个非压缩前缀节点。
将 A 节点挂在和 a 相同的父节点上。
同上,在 bcd 和 abc 这两个节点下挂空子节点来分别表示两个 key。

删除 key
删除一个 key 的流程比较简单,找到 iskey 的节点后,向上遍历父节点删除非 iskey 的节点。如果是非压缩的父节点并且 size > 1,表示还有其他非相关的路径存在,则需要按删除子节点的模式去处理这个父节点,主要是做 memove 和 realloc。
合并 key
删除一个 key 之后需要尝试做一些合并,以收敛树的高度。 合并的条件是:
iskey=1的节点不能合并- 子节点只有一个字符
- 父节点只有一个子节点(如果父节点是压缩前缀的节点,那么只有一个子节点,满足条件。如果父节点是非压缩前缀的节点,那么只能有一个字符路径才能满足条件)
Radix 总结
1、Redis 用到了 Radix 树来存储 key,Redis Stream 中的 key 也用到了 Radix 树。
2、Radix 树是压缩版的 Trie 树。
3、计算机处理 Radix 树是比较二进制位,和我们的直觉会有所偏差。
4、Radix 和 Trie 树对于字符串的检索,特别是有公共前缀的场景。如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能。总之对于字符串的检索,Trie 类树都比较适合,比如本文中的 Redis 的 key 这样的场景就非常适合。